
by Anil Jalela | Sep 2, 2024 | DevOps, Linux
There are more than 379 database servers in use around the world today. Among them, MongoDB stands out as a top performer, surpassing databases like HBase, Neo4j, Riak, Memcached, RavenDB, CouchDB, and Redis. Tech giants like Google, Yahoo, and Facebook rely on MongoDB in their production environments.In the DB-Engines ranking, MongoDB holds the 5th position overall, following:
Oracle
MySQL
Microsoft SQL Server
PostgreSQL
MongoDB
Notably, MongoDB is also ranked as the number one NoSQL database.
| RDBMS |
Mongo |
| Database |
database |
| table |
Collection |
| Record |
Document |
| Joins |
Embedded Object/Document |
Mongo works perfectly with most all programming languages.
Also, mongo works with Windows and Linux with the same performance and without issues.
Mongo provides Replication, Sharding, Aggregation, and indexing features.
Mongo is an object-oriented and schema-less database.
Mongo is based on JavaScript, and all documents (Records) are presented in JSON format. Also, in Mongo, everything is an object. In Mongo 1st field, the compulsory field is _id which is not skippable.
{
_id: numeric or numeric-alphabetical string or,it set automatically. Mongo id is a 12-byte Object id that is a 4-byte time-stamp with 5 bytes of any random value and 3 bytes of a counter value.
}
mongo document stores like
the document content single field, array, sub-document (join), or, an array of sub-document.
{
_id: 1
First name: Anil,
middle name : Jasvantray,
last name: Jalela
Mobile: [9619904949,2573335,2567580]
}
install mongo:-
| 1 |
add Repo |
echo “deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu focal/mongodb-org/6.0 multiverse” > /etc/apt/sources.list.d/mongodb-org-6.0.list |
| 2 |
add Key |
wget -qO – https://www.mongodb.org/static/pgp/server-6.0.asc | sudo apt-key add – |
| 3 |
update package list |
apt-get update |
| 4 |
install mongo server |
apt-get install -y mongodb-org && apt-get install mongodb-org-server |
| 5 |
change dir for modification |
cd /etc/
|
| 6 |
rename conf |
mv mongod.conf mongod.conf_org |
| 7 |
vi mongod.conf and add the below content into this. |
|
| 8 |
|
# mongod.conf
# for documentation of all options, see:
# http://docs.mongodb.org/manual/reference/configuration-options/
# Where and how to store data.
storage:
dbPath: /var/lib/mongodb
# engine:
# wiredTiger:
# where to write logging data.
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongod.log
# network interfaces
net:
port: 27017
bindIp: 0.0.0.0
# how the process runs
processManagement:
timeZoneInfo: /usr/share/zoneinfo
security:
keyFile: /etc/keyfile-mongo
authorization: enabled
#operationProfiling:
#replication:
# replSetName: “election01”
#sharding:
## Enterprise-Only Options:
#auditLog:
#snmp: |
| 9 |
kerate key file on master for replica set |
openssl rand -base64 756 > /etc/keyfile-mongo |
| 10 |
change permission |
chmod 600 /etc/keyfile-mongo && ll /etc/keyfile-mongo |
| 11 |
change onership of files |
chown mongodb:mongodb /etc/mongod.conf /etc/keyfile-mongo |
| 12 |
start mongo |
sudo systemctl start mongod |
| 13 |
start mongo on system boot |
sudo systemctl enable mongod |
| 14 |
check mongo status |
sudo systemctl status mongod |
| 15 |
mongo login command |
mongosh |
| 16 |
use mongo database |
use admin |
| 17 |
set mongo password |
db.createUser(
{
user: “mongoadmin”,
pwd: passwordPrompt(),
roles: [ { role: “root”, db: “admin” }, “readWriteAnyDatabase” ]
}
) |
| 18 |
|
mongosh –username=mongoadmin –password=yourpass –authenticationDatabase admin |
| 19 |
create database |
use nitwings
|
| 20 |
drop database |
“use nitwings” and then “db.dropDatabase()”
|
| 21 |
create database-specific user |
db.createUser({
user: “blackpost”,
pwd: passwordPrompt(),
roles: [
{ role: “readWrite”, db: “nitwings” }
],
mechanisms: [“SCRAM-SHA-256”],
authenticationRestrictions: [
{
clientSource: [“0.0.0.0/0”]
}
]
}) |
| 22 |
drop user |
“use admin” and then db.dropUser(“blackpost”); |
| 23 |
show users
|
db.getUsers() |
| 24 |
create collection |
use nitwings
db.createCollection(“testCollection”) |
25
|
Insert One Document into collection
|
db.testCollection.insertOne({ name: “test”, value: 123 }) |
| 26 |
Insert many Document into collection
|
db.testCollection.insertMany([{ name: “blackpost”, value: 789 }, { name: “nitwings”, value: 456 }]) |
27
|
create Index
|
db.testCollection.createIndex({ name: 1 }); |
| 28 |
check index created or not for collection
|
db.testCollection.getIndexes()
|
| 29 |
find document
|
nitwings> db.testCollection.findOne({ name: “blackpost” })
{
_id: ObjectId(’66d485a63c3f4eb31f5e739c’),
name: ‘blackpost’,
value: 789
} |
| 30 |
update document
|
nitwings> db.testCollection.updateOne({ name: “blackpost” }, { $set: { name: “aniljalela” } })
{
acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 1,
upsertedCount: 0
}
nitwings> db.testCollection.findOne({ name: “aniljalela” })
{
_id: ObjectId(’66d485a63c3f4eb31f5e739c’),
name: ‘aniljalela’,
value: 789
}
nitwings> |
| 31 |
delete document
|
nitwings> db.testCollection.deleteOne({ name: “aniljalela” })
{ acknowledged: true, deletedCount: 1 }
nitwings> |
| |
show collections and drop collection
|
nitwings> show collections
nitwings> db..drop() |
| 32 |
backup database |
mongodump –db nitwings –out /opt/backup/ –username mongoadmin –password yourpass –authenticationDatabase admin |
| 33 |
backup database from remote |
mongodump –host 10.10.10.10 –port 27017 –db nitwings –out /opt/backup/ –username mongoadmin –password yourpass –authenticationDatabase admin |
| 34 |
mongo all database |
mongodump –out /backups/all_databases_backup –username mongoadmin –password yourpass –authenticationDatabase admin
|
| 35 |
mongo all database from remote |
mongodump –host 10.10.10.10 –port 27017 –out /path/to/backup /opt/backup/ –username mongoadmin –password yourpass –authenticationDatabase admin |
| 36 |
restore database dump
|
mongorestore –host 10.10.10.10 –port 27017 –db nitwings –username mongoadmin –password yourpass –authenticationDatabase admin /opt/backup/nitwings |
| 37 |
drop existing DB and restore db
|
mongorestore –host 10.10.10.10 –port 27017 –db nitwings –username mongoadmin –password yourpass –authenticationDatabase admin –drop /opt/backup/nitwings |
| 38 |
restore all databases
|
mongorestore –host 10.10.10.10 –port 27017 –username mongoadmin –password yourpass –authenticationDatabase admin /opt/backup/ |
39
|
drop and restore all databases
|
mongorestore –host 10.10.10.10 –port 27017 –username mongoadmin –password yourpass –authenticationDatabase admin –drop /opt/backup/ |
| 40 |
restore specific collection
|
mongorestore –host 10.10.10.10 –port 27017 –db nitwings –collection –username mongoadmin –password yourpass –authenticationDatabase admin /opt/backup/nitwings/.bson |
If the –drop option is not used with mongorestore, MongoDB restores data without dropping existing collections. If a collection already exists, mongorestore merges the backup with the current data. Documents with the same _id are not overwritten; instead, they are skipped to avoid duplicates. New collections from the dump are created if they don’t exist. This approach can lead to inconsistent or duplicated data, especially if the data structure has changed since the backup was created, potentially causing incorrect query results. Indexes are restored as in the dump, but existing indexes are not recreated, and mismatched index specifications may cause the restore to fail.
Replica set:-
1.1.1.1 production-mongodb-01 master-node1
2.2.2.2 production-mongodb-02 slave-node1
3.3.3.3 production-mongodb-03 slave-node2
(1) Install Mongo on all servers using the above steps from 1 to 17
(2) un-comment below lines from conf
replication:
replSetName: “election01” |
(3) keyFile: This is used for internal authentication between MongoDB instances in a replica set or sharded cluster.
It ensures that only authorized MongoDB instances can communicate with each other.
scp /etc/keyfile-mongo 2.2.2.2: /etc/keyfile-mongo
scp /etc/keyfile-mongo 3.3.3.3: /etc/keyfile-mongo |
(4) restart master and slave and log in to Mongo to start replication
| 1 |
login master |
mongosh –username=mongoadmin –password=yourpass –authenticationDatabase admin |
| 2 |
Initiate replication |
rs.initiate() |
| 3 |
add replica |
rs.add(“2.2.2.2”)
rs.add(“3.3.3.3”) |
| 4 |
check replication status |
rs.status() |
| 5 |
remove the replica from the replication |
rs.remove(“hostname:port”) |
| 6 |
|
rs.reconfig({}) |
| 7 |
|
db.serverStatus() |
| 8 |
|
db.currentOp() |
| 9 |
|
db.repairDatabase() |
| 10 |
|
db.stats()
db.collection.stats() |
by Anil Jalela | Aug 28, 2024 | DevOps, Linux
Email Security and Privacy Considerations
Email security is crucial for managing unwanted events by preventing them or mitigating potential damage and loss. Ensuring email security involves addressing the entire process, considering the environment and risk conditions.
Vulnerabilities in Email Security
The infrastructure of internet email originates from the ARPAnet, where the primary concern was reliable message delivery, even during partial network failures. Confidentiality, endpoint authentication, and non-repudiation were not priorities, leading to significant vulnerabilities in modern email communication. As a result, an email message is susceptible to unauthorized disclosure, forgery, and integrity loss.
While these vulnerabilities stem from lower-level internet protocols (such as TCP/IP), they could have been mitigated by email protocols like SMTP and MIME. However, during their design, email was primarily used within the scientific community, where security concerns were minimal. The S/MIME standard now addresses these issues by providing cryptographic security services, including authentication, message integrity, non-repudiation of origin, and confidentiality. Despite widespread commercial support for S/MIME, interoperability issues persist, preventing it from becoming a universal standard.
Message Forgery
Message forgery is a significant concern in email security, where an attacker can manipulate an email to appear as though it was sent by someone else. This can be done by altering headers such as the “From” or “Date” fields. A forged email can deceive recipients into believing the message is legitimate, leading to potential security breaches. Detecting forged emails requires analyzing the email headers and understanding the underlying data, but most users lack the expertise to do so. Although email systems have mechanisms to detect and prevent forgery, they are not foolproof, and the risk remains significant.
The Role of DMARC, SPF, and DKIM
To combat email forgery, three key technologies are widely used: DMARC, SPF, and DKIM.
- SPF (Sender Policy Framework): SPF is an email authentication method that allows domain owners to specify which IP addresses are authorized to send emails on behalf of their domain. This is done through DNS records. When an email is received, the recipient’s mail server checks the SPF record to ensure the email is coming from an authorized source. If it isn’t, the email can be flagged as potentially fraudulent.
- DKIM (DomainKeys Identified Mail): DKIM provides a way to validate that an email was sent from the domain it claims to be sent from. It uses cryptographic signatures to verify that the email content hasn’t been altered in transit. The signature is generated by the sender’s mail server and verified by the recipient’s mail server using public keys published in the sender’s DNS records.
- DMARC (Domain-based Message Authentication, Reporting, and Conformance): DMARC builds on SPF and DKIM by allowing domain owners to publish a policy in their DNS records that instructs receiving mail servers on how to handle emails that fail SPF or DKIM checks. DMARC also provides a mechanism for domain owners to receive reports on how their email domain is being used, which helps in identifying and stopping fraudulent activities.
By implementing SPF, DKIM, and DMARC, organizations can significantly reduce the risk of email spoofing and improve the overall security of their email communications.
Brand Indicators for Message Identification (BIMI)
BIMI is a newer email specification that works alongside DMARC to provide visual verification of an email’s authenticity. With BIMI, organizations can display their brand logos in the recipient’s inbox, next to the email message, as a sign of authenticity. This visual indicator helps recipients quickly identify legitimate emails from trusted brands and enhances email security by making it more difficult for attackers to impersonate a brand. However, BIMI adoption is still in its early stages, and its effectiveness relies on widespread adoption by both senders and email clients.
Phishing
Phishing is a form of cyber fraud that uses deceptive emails to acquire confidential information, such as usernames, passwords, and credit card details. Phishing emails often masquerade as legitimate communications from trusted entities, tricking recipients into providing sensitive information. The impact of phishing can be severe, leading to financial loss and compromised personal information. Phishing attacks are becoming increasingly sophisticated, making it essential for users to be vigilant and for organizations to implement robust security measures.
Email Spam
Spam is the unsolicited flood of emails that clogs inboxes and hampers effective communication. It serves as a form of noise that obscures meaningful messages. The volume of spam has grown so significantly that it often surpasses the number of legitimate emails. While spammers typically aim to promote products or services, the sheer volume of spam can overwhelm email systems, leading to potential denial of service.
Anti-Spam Filtering
Anti-spam filters are essential tools in combating spam. These filters analyze incoming emails and identify characteristics typical of spam, such as suspicious subject lines, content, or sender information. Depending on the filter’s configuration, suspected spam can either be marked and moved to a special folder or discarded entirely. However, setting up anti-spam filters is a delicate process. An overly aggressive filter may result in false positives, where legitimate emails are mistakenly classified as spam, leading to potential loss of important communication.
Anti-spam filtering is an ongoing challenge, as spammers continually adapt their techniques to bypass filters. Advanced filtering technologies, such as machine learning algorithms, have improved the accuracy of spam detection, but no system is entirely foolproof.
Ensuring Message Authenticity with GPG
GPG (GNU Privacy Guard) is a popular tool used for encrypting and signing emails, ensuring that the contents are secure and the sender is authenticated. By using GPG, both the sender and recipient can verify the authenticity of the email and ensure that it has not been tampered with during transmission. GPG works by using a pair of cryptographic keys – one public and one private. The sender uses the recipient’s public key to encrypt the message, and the recipient uses their private key to decrypt it. Additionally, the sender can sign the email with their private key, allowing the recipient to verify the sender’s identity with the corresponding public key.
Ensuring Message Authenticity
Message authenticity refers to the assurance that an email originates from the claimed sender and has not been tampered with during transmission. According to RFC 2822, email headers like Date and From are crucial in establishing authenticity, but these can be easily manipulated, making it challenging to verify the true origin of an email.
In business, email authenticity is generally assumed unless there are clear signs of forgery. However, in archival processes, verifying authenticity is more complex, and additional measures, such as electronic signatures or certified email services, can help ensure the integrity and authenticity of messages.
Certified Email Services
Certified email services, like Italy’s Posta Elettronica Certificata (PEC), provide a legal guarantee of message authenticity and integrity. These services require users to be registered with certified providers who authenticate the sender and issue electronic receipts proving the message’s dispatch and delivery. Such services offer a higher level of security and can be legally binding in disputes.
Privacy Concerns
Email messages can easily be disclosed without authorization, posing privacy risks such as identity theft. To mitigate these risks, sensitive information should either be excluded from emails or protected through encryption. Privacy concerns are often more focused on unauthorized mailbox access rather than message interception during transmission.
In many countries, email is afforded the same privacy protections as traditional mail, with strict regulations governing who can access a user’s mailbox. These regulations vary by country and can significantly impact email recordkeeping policies, balancing the need to preserve potentially legally relevant information with privacy considerations.
Some organizations address privacy concerns by obtaining explicit consent from employees to access their company mailboxes or by allowing users to tag messages as public or private. However, these practices may not always align with national privacy laws.

by Anil Jalela | Oct 23, 2022 | DevOps
Maven is a tool that can now be used for building and managing any Java-based project. We hope that we have created something that will make the day-to-day work of Java developers easier and generally help with the comprehension of any Java-based project.
Maven’s Objectives:-
Maven’s primary goal is to allow a developer to comprehend the complete state of a development effort in the shortest period of time. In order to attain this goal, Maven deals with several areas of concern:-
Making the build process easy.
Providing a uniform build system.
Providing quality project information.
Encouraging better development practices.
Making the build process easy.
While using Maven doesn’t eliminate the need to know about the underlying mechanisms, Maven does shield developers from many details.
Providing a uniform build system:-
Maven builds a project using its project object model (POM) and a set of plugins. Once you familiarize yourself with one Maven project, you know how all Maven projects build. This saves time when navigating many projects.
Providing quality project information:-
Maven provides useful project information that is in part taken from your POM and in part generated from your project’s sources. For example, Maven can provide:
Change log created directly from source control.
Cross-referenced sources.
Mailing lists are managed by the project.
Dependencies used by the project.
Unit test reports including coverage.
Third-party code analysis products also provide Maven plugins that add their reports to the standard information given by Maven.
Providing guidelines for best practices development:-
Maven aims to gather current principles for best practices development and make it easy to guide a project in that direction. For example, specification, execution, and reporting of unit tests are part of the normal build cycle using Maven. Current unit testing best practices were used as guidelines:
Keeping test source code in a separate, but parallel source tree. Using test case naming conventions to locate and execute tests. Having test cases set up their environment instead of customizing the build for test preparation.
Maven also assists in project workflows such as release and issue management.
Maven also suggests some guidelines on how to lay out your project’s directory structure. Once you learn the layout, you can easily navigate other projects that use Maven.
While Maven takes an opinionated approach to project layout, some projects may not fit with this structure for historical reasons. While Maven is designed to be flexible to the needs of different projects, it cannot cater to every situation without compromising its objectives. If your project has an unusual build structure that cannot be reorganized, you may have to forgo some features or the use of Maven altogether.
What is Maven Not?
You might have heard some of the following things about Maven:-
Maven is a site and documentation tool.
Maven extends Ant to let you download dependencies.
Maven is a set of reusable Ant scriptlets.
While Maven does these things, as you can read above in the What is Maven? section, these are not the only features Maven has, and its objectives are quite different.
| 1 |
https://maven.apache.org/download.cgi |
Find latest version of Maven |
| 2 |
Cd /tmp && wget https://dlcdn.apache.org/maven/maven-3/3.8.6/binaries/apache-maven-3.8.6-bin.tar.gz |
Download latest in /tmp |
| 3 |
Tar -zxvf apache-maven-3.8.6-bin.tar.gz |
Extract project |
|
mv apache-maven-3.8.6 /opt/maven |
Set maven home |
| 4 |
echo ‘export M2_HOME=/opt/maven’| tee -a /etc/profile |
Set M2_HOME for binary environment |
| 5 |
echo ‘export MAVEN_HOME=/opt/maven’| tee -a /etc/profile |
Set MAVEN_HOME |
| 6 |
echo ‘ export PATH=${M2_HOME}/bin:${PATH}’| tee -a /etc/profile |
Set binary environment |
| 7 |
source /etc/profile |
export configurations in current system environment |

by Anil Jalela | Oct 21, 2022 | DevOps
Jenkins:-
→ Jenkins is an Open-Source project Written in Java that runs on Windows, macOS, and Other Unix-like Operating Systems. It is free, Community Supported, and might be your first-choice tool for CI.
→ Jenkins automates the entire Software development life Cycle
→ Jenkins was Originally developed by Sun Microsystem in 2004 under the name Hudson.
→ The project was later named Jenkins when Oracle bought Microsystems.
→ It Can run on any major platform without any Compatibilities issues.
→ Whenever developers Write Code, we integrate all that Code of all developers at that point in time and we build, test, and deliver/Deploy to the client. This process is called CI/CD ..
→ Jenkins helps us to achieve fast development.
→ Because of CI, Now bugs will be reported fast and get rectified fast So the entire Software development happens fast.
Workflow of Jenkins:-
→ We Can attach git, Maven, Selenium, Sonarqube, and Artifactory plugins to Jenkins.
→ Once developers put Code in GitHub, – Jenkins pulls that Code & sends to Maven for build
→ Once the build is done Jenkins pulls that Code and sends it to Selenium for testing.
→ Once testing is done, then Jenkins will pull that Code and Send it to artifactory (archive) as per requirement and so on.
→ We Can also deploy codes with Jenkins.
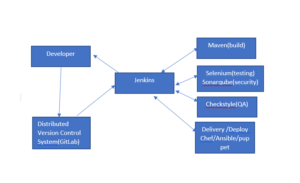
Build means=( compile, code review, unit testing, Integration testing, packaging[tar,jar,exe] )
Advantages of Jenkins: –
→ It has lots of plug-ins available
→ You Can Write your own plug-in.
→ You Can use Community Plug-in.
→ Jenkins is not just a tool. It is a framework i.e.: – You Can do whatever you want All you need is plug-ins.
→ We Can attach Slaves (nodes) to Jenkins master. It instructs others (slaves) to do Job. If slaves are not available Jenkins itself does the job.
→ Jenkins also behaves as a crone Server Replacement. i.e.: – Can do the scheduled task.
→ It Can Create Labels
| 1 |
yum install yum install fontconfig java-11-openjdk.x86_64 |
install java |
| 2 |
alternatives –config java |
the set version of java |
| 3 |
cp /etc/profile /etc/profile_backup |
backup profile |
| 4 |
echo ‘export JAVA_HOME=/usr/lib/jvm/ /usr/lib/jvm/jre_11_openjdk’ |tee -a /etc/profile |
export java development kit home |
| 5 |
echo ‘export JRE_HOME=/usr/lib/jvm/jre’ | tee -a /etc/profile |
export JVM home |
| 6 |
source /etc/profile |
export configurations in the current system environment |
| 7 |
wget -O /etc/yum.repos.d/jenkins.repo https://pkg.jenkins.io/redhat-stable/jenkins.repo |
Download the stable repo for yum |
| 8 |
rpm –import https://pkg.jenkins.io/redhat-stable/jenkins.io.key |
Import key for package signature verification |
| 9 |
yum install jenkins |
Install Jenkins |
| 10 |
systemctl start jenkins.service |
Start Jenkins service |
| 11 |
systemctl enable jenkins.service |
Enable Jenkins service |
what needs to learn in Jenkins?
Introduction to Jenkins
Introduction to Continuous Integration
Continuous Integration vs Continuous Delivery
Jenkins Overview
Characteristics and features
Architecture
Concepts and Terms
Benefits and Limitations
Installation and Configuration
Jenkins Installation and Configuration
Plug-ins Overview
Integration with Git
Integration with Maven
Integration with Java
Installing plugins
Setting up Build Jobs
Jenkins Dashboard
Create the first job
Running the first job
Manage jobs – failing, disable, update and delete
Pipeline with Jenkinsfile
Freestyle Project Configuration
Git Hooks and Other Build Triggers
Workspace Environment Variables
Parameterized Projects
UpstreamDownstream Projects and the Parameterized Trigger Plugin
Build a Java application with Maven using Jenkins
Continuous Delivery Pipeline
Publishing Build Artifacts
Deployment Plug-in setup and configuration
Auto Deployment of build artifacts into the target server
Deploy a Java application with Maven using Jenkins
Executing selenium Functional Testing with deployment
Management, Security and Best Practices
Managing and Monitoring Jenkins Server
Scaling Jenkins
Securing Jenkins
Adding Linux Node and executing job on it
Adding windows node and executing job on it
Configuring access control on Jenkins
Configuring role-based access control
Jenkins logs
Management
Credentials in Jenkins
Best Practices
Jenkins Pipeline
Writing Jenkins Pipeline file for java application build and deployment
Storing Jenkins in git and configuring webhook
Difference between declarative and scripted pipeline
Specify an agent in the pipeline
Parameters in Pipeline
Schedule build in the pipeline
Webhook in pipeline
Approval in pipeline
Approval with timeout in the pipeline
Variables in pipeline
Email notification in the pipeline
Post-build action in the pipeline
Parallel stages in the pipeline
Condition in pipeline
Selenium Functional Testing in the pipeline
by Anil Jalela | Aug 27, 2022 | DevOps, Linux
Chef:- Chef is pulled base automation tool which turns your code into infrastructure and helps to manage servers with increased uptime and performance, ensure compliance, minimize cost and reduce cost.
Configuration management:- configuration management is a method through which we automate admin tasks.
Chef-Client:- tool that pulls configuration from Chef-server with help of a knife and ohai.
Workstation:-work station is a server where DevOps write code (as recipe) and store it in a cookbook.
Cookbook:- Cookbook s place(folder) where DevOps write code as a recipe for automation.
Chef-server:- The server which is managing the cookbook and is connected between the node and Workstation.
Knife:- Knife is a command line tool that uploads the cookbook to the server and connects every node with Chef-server.
Node:- The server which required configuration. Which is communicating with Chef-server using the Chef-Client using the knife.
Bootstrap:- Bootstrap is a knife process that connects nodes and Chef-server for automation.
Chef supermarket:-the place where get recipes for automation.
Ohai:- Ohai is a database that stores the current configuration of the node and supplies it to the Chef-Client before connecting to the Chef server.
Idempotency:- Tracking the state of the system resources to ensure that changes should not reapply repeatedly.
Resource
=======
Resource:- Resources are components of a recipe used to manage the infrastructure with a different type of status. There can be multiple resources in a recipe that will help in configuring t and managing the infrastructure.
|
1
|
package
|
Manage packages on node
|
package ‘tar’ do
version ‘1.16.1’
action :install
end
|
|
service
|
Manage the service on node
|
service ‘apache’ do
action [ :enable, :start ]
retries 3
retry_delay 5
end
|
|
user
|
Manage the users on the node
|
user ‘aniljalela’ do
action :create
comment ‘cron user’
uid 1234
gid ‘1234’
home ‘/home/aniljalela’
shell ‘/bin/bash’
password ‘$1$JJsvHslasdfjVEroftprNn4JHtDi’
end
|
|
group
|
Manage groups
|
Group “vmail” do
action :create
member ‘dovecot’
append true
end
dont forgot create user before create group and must use append .
|
|
template
|
Manages the files with embedded ruby template
|
|
|
Cookbook file
|
Transfer the file from the files subdirectory in the cookbook to a location of node
|
|
|
file
|
Manage content of a file on the node
|
File “systeminfo” do
content “system information”
HOSTNAME: #{node [‘hostname’]}
IPADDRESS:#{node [‘ipaddress’]}
CPU: #{node [‘cpu’][‘0’ [‘mhz’]]}
MEMORY: #{node [‘’memory][‘total’]}
owner ‘root’
group ‘root’
end
|
|
execute
|
Executes a command on the node
|
execute 'apache_configtest' do
command '/usr/sbin/apachectl configtest'
end
or
Execute “run a script” do
command <<-EIH
chown apache:apache / home / anil / jalela -R
EOH
end
(remove space from path and note that (this commands runs on every calls)
|
|
cron
|
Edits an existing cron job file on the node
|
|
|
directory
|
Manage the directory on the node
|
|
|
git
|
|
git "#{Chef::Config[:file_cache_path]}/ruby-build" do
repository 'git://github.com/sstephenson/ruby-build.git'
reference 'master'
action :sync
end
bash 'install_ruby_build' do
cwd '#{Chef::Config[:file_cache_path]}/ruby-build'
user 'rbenv'
group 'rbenv'
code <<-EOH
./install.sh
EOH
environment 'PREFIX' => '/usr/local'
end
|
|
bash
|
|
bash 'install_ruby_build' do
cwd '#{Chef::Config[:file_cache_path]}/ruby-build'
user 'rbenv'
group 'rbenv'
code <<-EOH
./install.sh
EOH
environment 'PREFIX' => '/usr/local'
end
|
|
hostname
|
|
hostname 'statically_configured_host' do
hostname 'example'
ipaddress '198.51.100.2'
end
|
|
|
|
|
|
|
|
|
Chef-Workstation:-
wget https://packages.chef.io/files/stable/chef-workstation/22.7.1006/el/7/chef-workstation-22.7.1006-1.el7.x86_64.rpm
rpm -ivh chef-workstation-22.7.1006-1.el7.x86_64.rpm or
yum localinstall chef-workstation-22.7.1006-1.el7.x86_64.rpm
[root@srv25 ~]# which chef
/usr/bin/which: no chef in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin)
[root@srv25 ~]#
|
1
|
chef -v
|
Check chef version information.
|
Chef Workstation version: 22.7.1006
Cook style version: 7.32.1
Chef Infra Client version: 17.10.0
Chef InSpec version: 4.56.20
Chef CLI version: 5.6.1
Chef Habitat version: 1.6.420
Test Kitchen version: 3.3.1
|
|
2
|
mkdir /home/workstation-chef.blackpost.net/chef-repo/cookbooks -p
|
cookbooks is the main directory. We will create identical cookbooks into this, and
Create recopies in the identical cookbook.
|
|
|
3
|
cd /home/workstation-chef.blackpost.net/chef-repo/
cookbooks/
chef generate cookbook common-cookbook
|
Generate cookbook common-cookbook and we add recipes into the
common-cookbook
|
.
└── common-cookbook
├── CHANGELOG.md
├── chefignore
├── compliance
│ ├── inputs
│ ├── profiles
│ ├── README.md
│ └── waivers
├── kitchen.yml
├── LICENSE
├── metadata.rb
├── Policyfile.rb
├── README.md
├── recipes
│ └── default.rb
└── test
└── integration
└── default
└── default_test.rb
|
|
4
|
Cd /home/workstation-chef.blackpost.net/chef-repo/cookbooks/common-cookbook
chef generate recipe common-recipe
|
Generate recipe name common-recipe
|
|
|
5
|
Cd /home/workstation-chef.blackpost.net/chef-repo/cookbooks/
vi common-cookbook /recipes/common-recipe.rb
|
Open generate common-recipe for add code.
|
|
|
6
|
Chef exec ruby -c common-cookbook /recipes/common-recipe.rb
|
Check code syntax of common-recipe
|
|
|
7
|
Chef-client -zr “recipe[common-cookbook::common-recipe”
|
Run recipe on local system.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Attributes:- attribute is a key-value pair that represents a specific detail about a node. Which is determine
(1) current state of the node.
(2) previous chef-client run the state.
(3) what stats of the node when checking client run?
Attributes use in node. Cookbook, roles, environment, and recipes.
|
No
|
Name
|
Priority
|
|
1
|
Default
|
6
|
|
2
|
Force-default
|
5
|
|
3
|
Normal
|
4
|
|
5
|
Override
|
3
|
|
5
|
Force-override
|
2
|
|
6
|
Automatic
|
1
|
Convergence:- run chef-client to apply the recipe to bring the node into the desired state this process is known as Convergence.
Runlist:- run recipes in a sequence order that we have mentioned in the run list. Using a run list we can run multiple recipes but the condition is there must be only one recipe from one cookbook.
Chef-client -zr “recipe[common-cookbook::common-recipe], recipe[apache-cookbook::apache-recipe] ”
Include recipe:- from one recipe to call another recipes are present in the same cookbook. For include, you can use any recipe but recommend is the default.
cd /home/workstation-chef.blackpost.net/chef-repo/cookbooks/common-cookbook
vi common-recipe/default.rb
inclde_recipe “common-cookbook::common-recipe”
inclde_recipe “Apache-cookbook::Apache-recipe”
chef-client -zr “recipe[common-cookbook::default]”
Chef-Server:-
Create an account on https://manage.chef.io
Create organization via the Administration tab
We can create or manage multiple organizations on “manage.chef.io”
Each organization is for one company.
Download chef-starter.zip on your workstation and overwrite it on chef-repo
|
root@vps205204 1]# unzip chef-starter.zip
Archive: chef-starter.zip
: chef-repo/README.md
creating: chef-repo/cookbooks/
: chef-repo/cookbooks/chefignore
creating: chef-repo/cookbooks/starter/
: chef-repo/cookbooks/starter/metadata.rb
creating: chef-repo/cookbooks/starter/files/
creating: chef-repo/cookbooks/starter/files/default/
: chef-repo/cookbooks/starter/files/default/sample.txt
creating: chef-repo/cookbooks/starter/templates/
creating: chef-repo/cookbooks/starter/templates/default/
: chef-repo/cookbooks/starter/templates/default/sample.erb
creating: chef-repo/cookbooks/starter/attributes/
: chef-repo/cookbooks/starter/attributes/default.rb
creating: chef-repo/cookbooks/starter/recipes/
: chef-repo/cookbooks/starter/recipes/default.rb
: chef-repo/.gitignore
creating: chef-repo/.chef/
creating: chef-repo/roles/
: chef-repo/.chef/config.rb
: chef-repo/roles/starter.rb
: chef-repo/.chef/aniljalela.pem
[root@vps205204 1]#
|
|
cp -rpv chef-repo /home/workstation-chef.blackpost.net/chef-repo/
|
/home/workstation-chef.blackpost.net/chef-repo/.chef/config.rb is a knife file.
|
[root@vps205204 chef-repo]# cat /home/workstation-chef.blackpost.net/chef-repo/.chef/config.rb
# See http://docs.chef.io/workstation/config_rb/ for more information on knife configuration options
current_dir = File.dirname(__FILE__)
log_level :info
log_location STDOUT
node_name “aniljalela”
client_key “#{current_dir}/aniljalela.pem”
chef_server_url “https://api.chef.io/organizations/blackpost”
cookbook_path [“#{current_dir}/../cookbooks”]
[root@vps205204 chef-repo]#
|
Check connection with the server.
|
[root@vps205204 chef-repo]# knife ssl check
Connecting to host api.chef.io:443
Successfully verified certificates from `api.chef.io’
[root@vps205204 chef-repo]#
|
Connect node with chef-server via workstations.
knife bootstrap <IP or FQDN> -N <NODE_NAME> -x <USER> — sudo — identity-file <SSH_PEM_FILE>
or
knife bootstrap node_name -x root -P password –sudo
|
Knife bootstrap 10.01.11.1 –ssh-user ec2-user –sudo -i key.pem -N node1
|
Upload cookbook on server and list it
knife cookbook upload cookbook-name
|
knife cookbook upload common-cookbook
knife cookbook list
|
Apply recipe to specific node:-
|
Knife node run_list set node1 “recipe[common-cookbook::common-recipe]”
|
To see a list of cookbooks that are present in the chef server
|
[root@vps205204 chef-repo]# knife cookbook list
common-cookbook 0.1.0
[root@vps205204 chef-repo]#
|
To delete cookbook from chef server
|
Knife cookbook delete common-cookbook -y
|
To see the list of nodes present in the chef server.
To delete a node from the server.
|
Knife node delete node-name -y
|
To see list of clients which are present in chef-server
To delete the client from the chef-server.
|
Knife client delete client-name -y
|
To see a list of roles that are present in the chef-server.
to delete roles from chef-server
|
Knife role delete role-name -y
|
Role:-
Instead of assigning recipes using knife run_list assign a role to the server and add Recipes into the role
|
Cd /home/workstation-chef.blackpost.net/chef-repo/roles/
vi webserver.rb and add below code
name “webserver”
description “create web servers”
run_list “recipe[common-cookbook::common-recipe]”,“recipe[apache-cookbook::apache-recipe]”
|
Upload role chef-server
|
Knife role from file roles/devops.rb
|
If you want to see the role created or not on the server.
Bootstrap the node.
|
Knife bootstrap node-ip –ssh-user centos –sudo (-i) node-key.pem -N node1
|
Assign run_list to node
|
knife node run_list set node1 “role[webserver]”
|
Show which node have which roles
|
knife node show node1 (node1 is node name)
|
You need to upload the recipe to the server.
|
knife cookbook upload common-cookbook
knife cookbook upload apache-cookbook
|
We can add recipes in two ways in the role.
|
vi webserver.rb and add below code
name “webserver”
description “create web servers”
run_list “recipe[common-cookbook::common-recipe]”,“recipe[apache-cookbook::apache-recipe]”
|
Or as below which include all the recipes of common-cookbook and apache-cookbook.
|
vi webserver.rb and add below code
name “webserver”
description “create web servers”
run_list “recipe[common-cookbook”,“recipe[apache-cookbook]”
|
Loop in recipe
|
%w (tar zip mysql httpd wget vim)
.each do |p|
package p do
action :install
end
end
|
by Anil Jalela | Aug 3, 2022 | DevOps, Linux
Git is free and open source software for distributed version control: tracking changes in any set of files, usually used for coordinating work among programmers collaboratively developing source code during software development. Its goals include speed, data integrity, and support for distributed, non-linear workflows (thousands of parallel branches running on different systems).
Git was originally authored by Linus Torvalds in 2005 for the development of the Linux kernel, with other kernel developers contributing to its initial development. Since 2005, Junio Hamano has been the core maintainer. As with most other distributed version control systems, and unlike most client-server systems, every Git directory on every computer is a full-fledged repository with complete history and full version-tracking abilities, independent of network access or a central server. Git is free and open-source software distributed under the GPL-2.0-only license.
Characteristics:-
Strong support for non-linear development
Distributed development
Compatibility with existing systems and protocols
Efficient handling of large projects
Cryptographic authentication of history
Toolkit-based design
Pluggable merge strategies
Garbage accumulates until collected
Periodic explicit object packing
* remote server = Linux system in the cloud
* client = local computer(window, Linux, Mac)
|
1
|
yum -y install git
|
For install Git
|
Install git on the remote server and On the client.
|
|
2
|
git –version
|
check the currently installed git version
|
|
|
3
|
git config –global user.name ‘Nitwings Server’
git config –global user.email ‘[email protected]’
|
Set a repository username and email to identify where to push or pull code from.
|
Set on remote Server.
|
|
4
|
git config –global user.name ‘Anil Jalela’
git config –global user.email ‘[email protected]’
|
Set a repository username and email to identify where to push or pull code from.
|
On client.
|
|
5
|
git config -l
|
list of information about git configuration including user name and email
|
On client and server.
|
|
6
|
mkdir /home/git-client.blackpost.net/public_html/repos/project-client
|
Creating Git repository Folder
|
On client.
|
|
7
|
git init
|
Initialize Git repository
|
On client.
|
|
8
|
mkdir /home/git-server.blackpost.net/public_html/repos/project-server
|
Initialize Git repository
|
On Server.
|
|
9
|
git init –bare
|
Initialize Git repository
|
On Server.
|
|
10
|
echo “Hello Nitwings” > /home/git-client.blackpost.net/public_html/repos/project-client/index.html
|
create 1st file in an empty repository
|
On client.
|
|
11
|
git status
git status –short
|
to check git status use the command “git status”
|
On client.
|
|
12
|
git add index.html
|
Add index.html in the current directory to the Staging Environment
|
On client.
|
|
13
|
git add –all
|
Add all files in the current directory to the Staging Environment
|
On client.
|
|
14
|
git add -A
git add .
|
Add all files in the current directory to the Staging Environment
|
On client.
|
|
15
|
git commit -m “this is our 1st project release”
|
Move from Staging to commit for our repo(master repo) when work is done.
-m = message
|
On client.
|
|
16
|
git commit -a
|
commit file directly in a master repo without adding a stage repo
|
|
|
17
|
git log
|
view master repo history for commits
|
|
|
18
|
git –help
|
For git help
–help instead of -help to open the relevant Git manual page
|
|
|
19
|
git help –all
or
git help –a
|
To list all possible commands
|
|
|
20
|
git add –help
|
git command -help
|
|
|
21
|
git branch branch-name
|
Create git branch
(brach create in same repo dir)
|
|
|
22
|
git branch
|
Show branch in the repo
|
|
|
23
|
Git checkout ‘branch-name’
|
Switched to branch
in branch working dir is same.
|
|
|
24
|
git checkout -b ‘fastfix’
|
Create fast-fix branch and use it for changes
|
|
|
25
|
git checkout master
git branch
|
Switched to branch ‘master’
and show all branch
|
|
|
26
|
git merge ‘fastfix’
|
merge the selected branch (master) with not selected branch name
|
|
|
27
|
git branch -d fastfix
|
Delete fast-fix branch
|
|
|
28
|
Git log
|
View the history of commits for the repository
|
|
|
29
|
touch .gitignore
git add .gitignore
git commit .gitignore
|
Create .gitignore file
and add and commit to ignoring some files and folders from the workspace
|
|
|
Vi .gitignore
*.txt
|
In .gitignore add a line to ignore all .txt files
|
|
|
30
|
Vi .gitignore
rndcode/
|
In .gitignore add a line to ignore all files in any directory named rndcode
|
|
|
31
|
Vi .gitignore
*.bat
!server.bat
|
In .gitignore, ignore all .bat files, except the server.bat
|
|
|
32
|
git log –oneline
|
Show the log of the repository, showing just 1 line per commit
|
|
|
33
|
git show commit-id
|
|
|
|
34
|
git log -10
|
|
|
|
35
|
git log –grep “word”
|
|
|
|
36
|
git stash
|
|
|
|
37
|
git stash list
|
|
|
|
38
|
git stash apply staash@{file number}
|
|
|
|
39
|
git stash clear
|
|
|
|
40
|
git reset file-name
|
|
|
|
41
|
git reset .
|
|
|
|
42
|
git reset –hard
|
|
|
|
43
|
git clean -n
|
|
|
|
44
|
git clean -f
|
|
|
|
45
|
git tag -a tagname -m “message” commit-id
|
|
|
|
46
|
git tag
|
|
|
|
git show tag-name
|
|
|
|
47
|
git -d tag tag-name
|
|
|
|
|
|
|
GitHub or Your Server Repo:-
|
git remote add origin github-url
|
Add a remote repository as an origin
|
|
|
Git fetch origin
|
Get all the change history of the origin for this branch
|
|
|
git merge origin/master
|
Merge the current branch with the branch master, on the origin
|
|
|
git pull origin
|
Update the current branch from its origin using a single command
|
|
|
git pull origin master
|
Update the current branch from the origin master using a single command
|
|
|
git push origin
|
push the current branch to its default remote origin
|
|
|
git push origin master
|
push the current branch to its default remote maser
|
|
|
Git branch -a
|
List all local and remote branches of the current Git
|
|
|
Git branch -r
|
List only remote branches of the current Git
|
|
|
git clone url
|
Clone the remote repository
|
|
|
git clon url project-client
|
Clone the repository https://blackpost.net/wings.git to a folder named “project-client“:
|
|
|
Git remote rename origin upstream
|
Rename the origin remote to upstream
|
|
|
git remote add ssh-origin user@blackpostnet:/git-reo-path/
|
Add a remote repository via SSH as an origin
|
|
|
Git remote set-url origin user@blackpostnet:/git-reo-path/
|
Replace remote origin URL
|
|
|
|
|
|
What needs to learn in Git?
Introduction
Understanding version control
The history of Git
About distributed version control
Who should use Git?
Installing Git on Windows
Installing Git on Linux
Configuring Git
Exploring Git auto-completion
Using Git help
Initializing a repository
Understanding where Git files are stored
Performing your first commit
Writing commit messages
Viewing the commit log
Exploring the three-trees architecture
The Git workflow
Using hash values (SHA-1)
Working with the HEAD pointer
Adding files
Editing files
Viewing changes with diff
Viewing only staged changes
Deleting files
Moving and renaming files
Undoing working directory changes
Unstaging files
Amending commits
Retrieving old versions
Reverting a commit
Using reset to undo commits
Demonstrating a soft reset
Demonstrating a mixed reset
Demonstrating a hard reset
Removing untracked files
Using gitignore
Understanding what to ignore
Ignoring files globally
Ignoring tracked files
Tracking empty directories
Referencing commits
Exploring tree listings
Getting more from the commit log
Viewing commits
Comparing commits
Branching overview
Viewing and creating branches
Switching branches
Creating and switching branches
Switching branches with uncommitted changes
Comparing branches
Renaming branches
Deleting branches
Configuring the command prompt to show the branch
Merging code
Using fast-forward merge vs true merge
Merging conflicts
Resolving merge conflicts
Exploring strategies to reduce merge conflicts
Saving changes in the stash
Viewing stashed changes
Retrieving stashed changes
Deleting stashed changes
Working with GitHub
Setting up a GitHub account
Adding a remote repository
Creating a remote branch
Cloning a remote repository
Tracking remote branches
Pushing changes to a remote repository
Fetching changes from a remote repository
Merging in fetched changes
Checking out remote branches
Pushing to an updated remote branch
Deleting a remote branch
Enabling collaboration
A collaboration workflow
Using SSH keys for remote login
Managing repo in GitHub
Managing users in GitHub
Managing keys in GitHub
Webhook in GitHub
Next update soon…